 Рассказывает
Рассказывает
Инга Лабахуа
Привет. Я Инга, основательница агентства Supprt.Science. Мы помогаем компаниям создавать дружелюбный клиентский сервис. В прошлом году один из наших клиентов спросил, можем ли мы сделать поддержку на GPT. Прозвучало как вызов: на рынке пока мало подобных кейсов — можно пересчитать по пальцам одной руки, и у нас была возможность стать первопроходцами. Мы ответили «да» и с головой погрузились в работу. Всего через 3,5 месяца мы запустили контекстного бота на основе GPT и уже на первых обращениях увеличили скорость и качество ответов клиентам — бот зачастую справлялся лучше, чем человек! Спешим поделиться результатами и опытом.
Чем LLM полезна в клиентской поддержке
На конференции Epiq Grow AI 2024 коллеги высказывали мнение, что если у компании до сих пор нет клиентской поддержки на GPT, она сильно отстала. Еще год назад я бы закидала спикеров «помидорами» за такие тезисы, но сейчас я как никто поддерживаю подобные высказывания. Я уверена, что люди должны выполнять более интересную и сложную работу, чем отвечать на часто задаваемые вопросы — для этого вполне сгодятся боты.
Внедрение любого бота ускоряет обработку клиентских обращений, а боты на базе GPT по нашему опыту отличаются еще и дружелюбным общением — мы под этим понимаем более качественное решение проблем клиентов и живой диалог. Чем «умнее» модель, чем больше информации ей «скормили», тем точнее и полнее она будет отвечать на вопросы.
Думаю, в ближайшие пару лет LLM станет маст хэв инструментом в клиентском сервисе. Поэтому чем быстрее компании начнут вникать в технологию и применять ее в бизнес-процессах, тем лучше.
Одним из барьеров, который пока отделяет бизнес от массового внедрения GPT-based сервиса, является недостаток экспертизы в промт-инжиниринге, что естественно, ведь эта область знаний относительно новая.
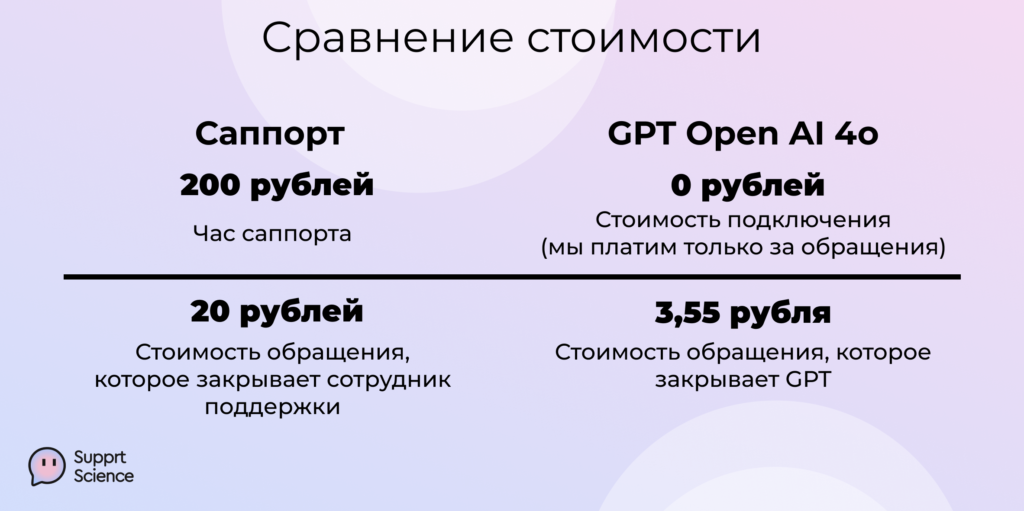
Мы тестировали разные LLM в течение длительного времени и сравнили стоимость одного ответа бота со стоимостью ответа от человека. Важно: в приведенных ниже данных не учтены косты онбординга, контроля качества и других сторонних процессов, которые сопутствуют работе службы поддержки.
А еще:
- GPT работает круглосуточно
- Может отвечать на любых языках
По нашим расчетам, внедрение LLM позволяет увеличить производительность примерно в три раза и сократить стоимость ответа в шесть раз — думаю, со временем она станет еще дешевле. В шесть раз позволяет сократить стоимость ответа внедрение LLM
Какие задачи GPT решает в нашей поддержке
Итак, наш клиент — это тревел агентство со службой поддержки, которая закрывает около 10 000 обращений в месяц.
Основная проблема — клиент хочет масштабироваться на международный рынок, и служба поддержки в этом случае становится узким местом. Необходимо было повысить ее «пропускную способность». Ситуация осложнялась тем, что обращения обрабатывались медленно и далеко не всегда качественно. Скорость ответа — 54 минуты на одно обращение, плюс масса недовольства от клиентов по качеству решения проблем. 54 минуты на одно обращение была скорость до внедрения бота А в специфических, сложных кейсах (инцидентах) — и того больше. Причины — плохо настроенный HelpDesk, отсутствие Базы Знаний и описанных процедур, неудобная админка. Мы посчитали: чтобы ответить на одно обращение, саппорту приходилось работать с десятком вкладок одновременно.
Клиенту нужен был инструмент, способный ускорить работу службы поддержки на всех этапах и линиях. Безусловно, перед этим необходимо было настроить HelpDesk, создать Базу Знаний и решить еще ряд проблем, поскольку одним внедрением LLM повысить скорость и качество поддержки не получится. У модели должны быть понятные и наполненные источники информации о тарифах, условиях, пользовательских сценариях и данных.
Нам предстояло создать контекстного бота на базе LLM, который будет выполнять следующие задачи:
- Консультировать клиентов
Бот может взять на себя ответы на клиентские запросы, с которыми способен справиться. Это могут быть как стандартные вопросы общего характера, так специфические кейсы, требующие понимания контекста и клиентского пути конкретного пользователя.
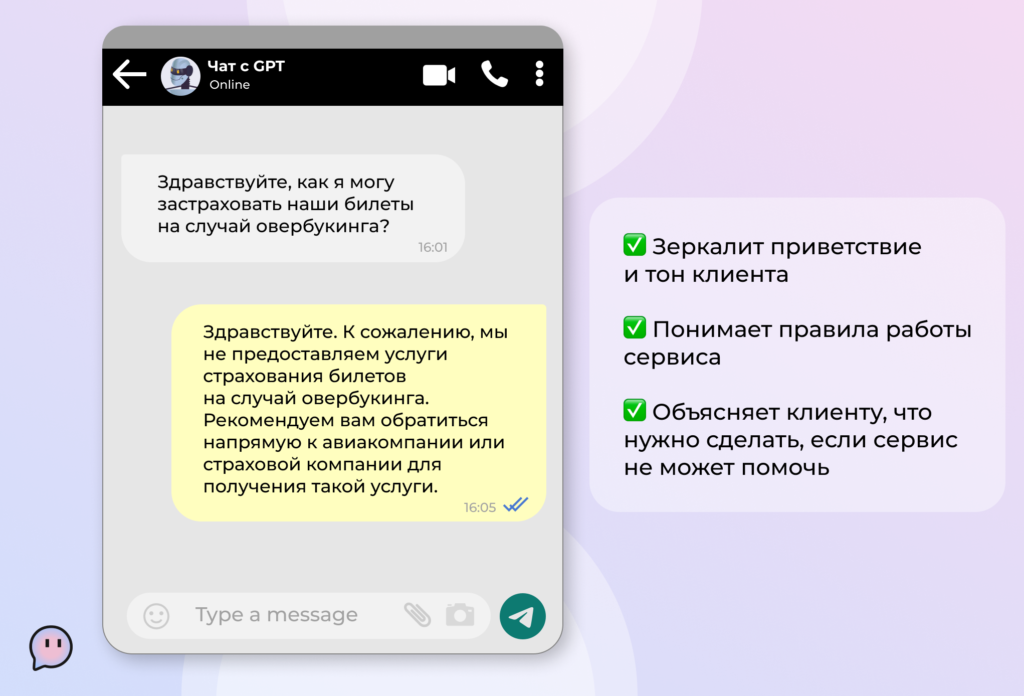
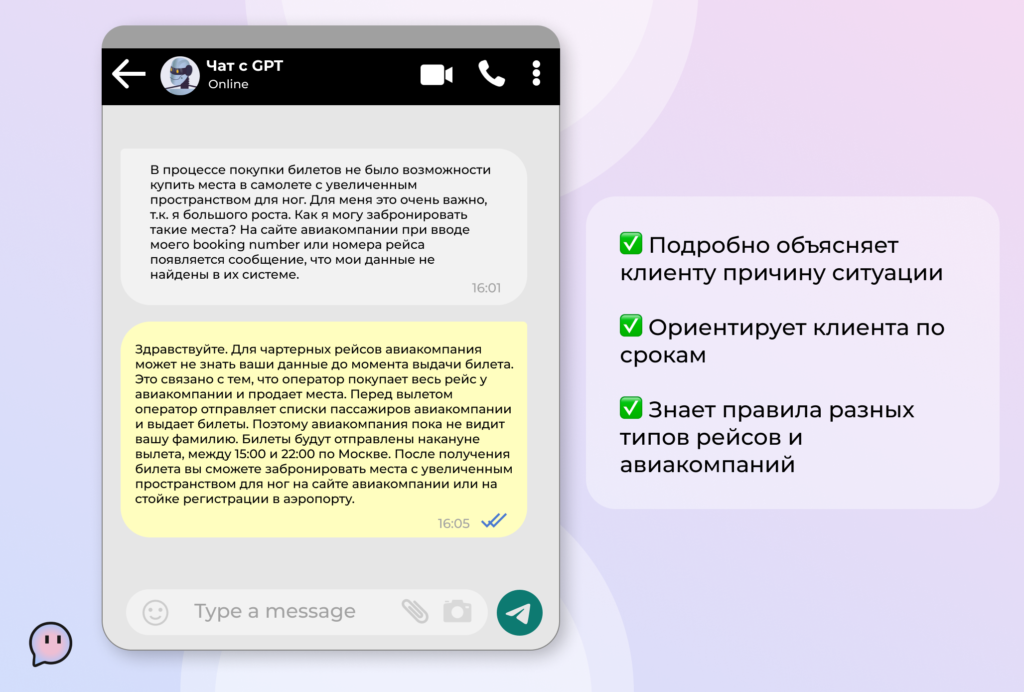
- Классифицировать обращения клиентов по тематикам, чтобы точнее и быстрее готовить ответы.
- Определять негативные кейсы или кейсы, требующие эскалации на человека. Бот должен уметь определять негатив и оперативно подключать саппорта к решению вопроса.
Нам было важно встроить бота, который не ухудшил бы клиентский опыт. Иными словами, клиент не должен догадываться, что общается с ботом, а не человеком. Качество коммуникации мы оценивали по внутренним метрикам, которые разработали сами. О них расскажем ниже.
По нашему опыту уже на первом этапе после внедрения LLM способна закрывать от 16% до 62% обращений на первой линии. от 16% до 62% обращений способна закрывать LLM на первом этапе внедрения Зависит от тематики и сложности запросов.
Например, высокий процент покрытия бот обеспечивает в тематике «Маршрутные квитанции» — за счет того, что мы автоматизировали отправку клиентам их билетов и данных для онлайн регистрации. Самый низкий процент наблюдается в тематике «Животные», поскольку добавить питомца — сложная внутренняя процедура, которая требует участия саппорта. В этом случае бот ограничивается тем, что собирает всю необходимую информацию для сотрудника поддержки.
Основные этапы и сроки внедрения LLM
С нашей стороны над проектом работали проектный менеджер и дизайнер диалогов (промт-инженер), со стороны клиента — проектный менеджер и fullstack разработчик. Соответственно, на нас были промтинг (то есть подготовка запросов для LLM), составление карт знаний, работа над качеством ответов и описание интеграции. На клиенте — экспертиза по продукту, непосредственно интеграция с бэкендом и базами данных.
Проект состоял из четырех основных этапов:
- Аудит, исследование, подготовка процедур и промтов
- Интеграция и тестирование
- Ответы клиентам
- Работа над качеством ответов и покрытием каналов связи
Этап 1. Аудит, исследование, подготовка процедур и промтов. Для начала мы посмотрели, какие решения есть на рынке, и насколько они отвечают нашим потребностям. Остановились на Open AI (начинали с 3,5, а сейчас отвечаем на 4o) как на самом стабильном и надежном варианте — эта LLM отлично обучена, умеет хорошо работать с контекстом и вести диалог. На самом деле, можно использовать и другие аналоги — главное, чтобы LLM отвечала вашим задачам и подходила по стоимости.
Параллельно с выбором языковой модели мы начали подготовку карт знаний, процедур и промтов. Запросили у клиента список тематик-интентов, с которыми обращаются в поддержку чаще всего, и прописали запросы и алгоритмы действия для контекстного бота.
Срок — 3 недели.
Этап 2. Интеграция и тестирование. LLM довольно проста в интеграции с бэкендом, HelpDesk и базами данных. Схема такая:
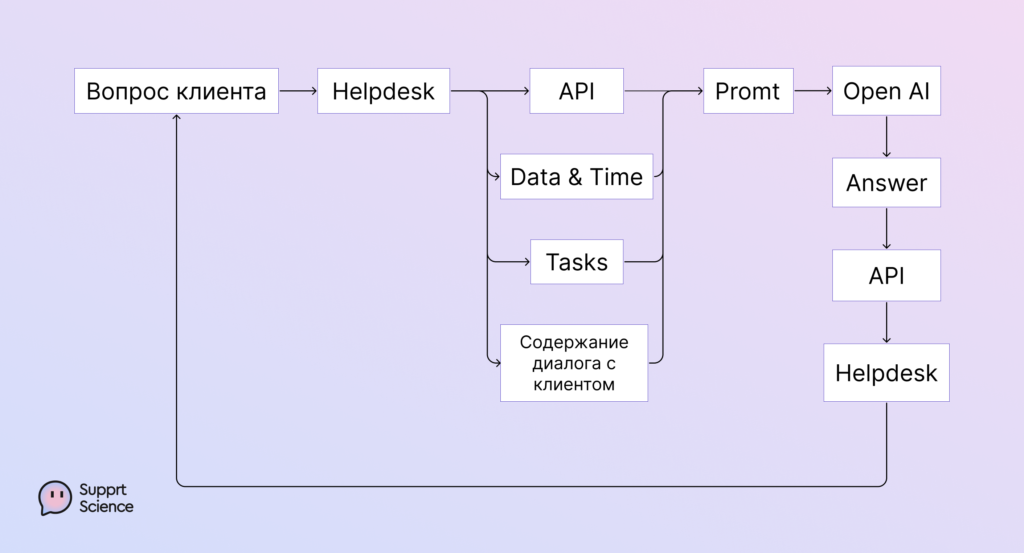
Тестирование мы проводили в две стадии:
- Тестирование в «песочнице». На этом этапе мы на тестовом стенде проверяли, насколько ответы контекстного бота соответствуют утвержденным требованиям и правилам. Мы брали реальные запросы от клиентов и задавали их боту. LLM собирала по ним информацию из доступных ей баз данных и выдавала ответ.
- Тестирование через модерацию саппортов. Когда мы убедились, что LLM отвечает в рамках заданных правил, мы открыли ее на саппортов. Контекстный бот сам составлял ответ и добавлял его в тикет как комментарий. Саппорт проверял текст на соответствие требованиям и либо отправлял его клиенту, либо дорабатывал. Таким образом, на этом этапе LLM выполняла только роль суфлера для саппорта.
Срок — 6 недель.
Этап 3. Ответы клиентам. Изначально мы планировали, что на первых порах бот будет отвечать на вопросы в рамках одной конкретной тематики. Например, только на вопросы по билетам. В процессе поняли, что вопросы сильно пересекаются и решили дать боту возможность отвечать на все, на что он способен. Если данных не хватало, он эскалировал тикет на человека, помечая, в какие сроки нужно ответить клиенту.
На 3 этапе процесс выглядел так: бот отвечает на вопрос клиента и если дальше по процедуре обращение решено, тикет перевешивается на сотрудника поддержки, и он помечает его как «выполненное». Таким образом мы осуществляем двухэтапную проверку за ботом.
Срок — 2 недели.
Этап 4. Работа над качеством ответов и покрытием каналов связи. Сюда вошли разработка карт знаний по оставшимся тематикам-интентам, настройка дашбордов для оценки работы LLM, настройка системы алертов, обучение команды заказчика промт-инжинирингу и доработке карт знаний.
Мы начали работать над проектом в сентябре 2023 года, а уже в середине декабря выкатили контекстного бота на клиентов. Итого внедрение заняло 3,5 месяца. Сейчас мы находимся на стадии повышения качества ответов. 3,5 месяца заняло внедрение LLM
Из чего складывается экономика внедрения LLM-based поддержки
Из затрат на:
- Разработку, а точнее на интеграцию LLM по API
- Обслуживание LLM: нужен проджект из команды поддержки на постоянку, который управляет знаниями, следит за качеством ответов.
- Использованные токены за ответы клиентам.
Что касается интеграции и поддержки бота на GPT, калькуляция следующая:
Стоимость запуска (Этапы 1-3)
Мы взяли зарплаты чуть выше рынка, чтобы точно уложиться в бюджет:
Проджект менеджер — 150 000 рублей в месяц;
Дизайнер диалога — 80 000 рублей в месяц;
Разработчик на 0,5 ставки — 200 000 рублей в месяц.
Итого: 1 505 000 рублей (стоимость всех этапов).
Стоимость поддержки качества (Этап 4)
Дизайнер диалогов — 80 000 рублей в месяц;
Разработчик 0,25 ставки — 100 000 рублей в месяц.
Итого: 180 000 рублей в месяц.
Теперь о токенах.
Токен — это минимальная единица измерения входного текста. Токеном может быть одна буква, одно слово или целая фраза — зависит от типа и задачи модели. Еще токены тратятся на действия, которые могут потребоваться для подготовки ответа. Например, если LLM для корректного ответа нужно перепроверить какие-либо данные.
Таким образом, чем сложнее запрос и длиннее ответ, тем дороже будет результат.
Рассмотрим на примере:

В данном случае к LLM предъявлялись следующие требования:
- соблюдение Tone of Voice компании;
- соответствие данным из Базы Знаний;
- проверка корректности данных из личного кабинета клиента;
- эскалация в случае ошибки.
То есть в процессе обработки LLM произвела несколько действий, затратив 2173 токена. Финальная стоимость составила 0,96 рубля. Если бы условий было меньше, то и стоимость была бы ниже.
Что касается средней стоимости одного реплая и тикета, то она следующая: 24 560 рублей траты в месяц при нагрузке в 4 400 тикетов

Метрики Успеха — как мы оцениваем качество ответов бота
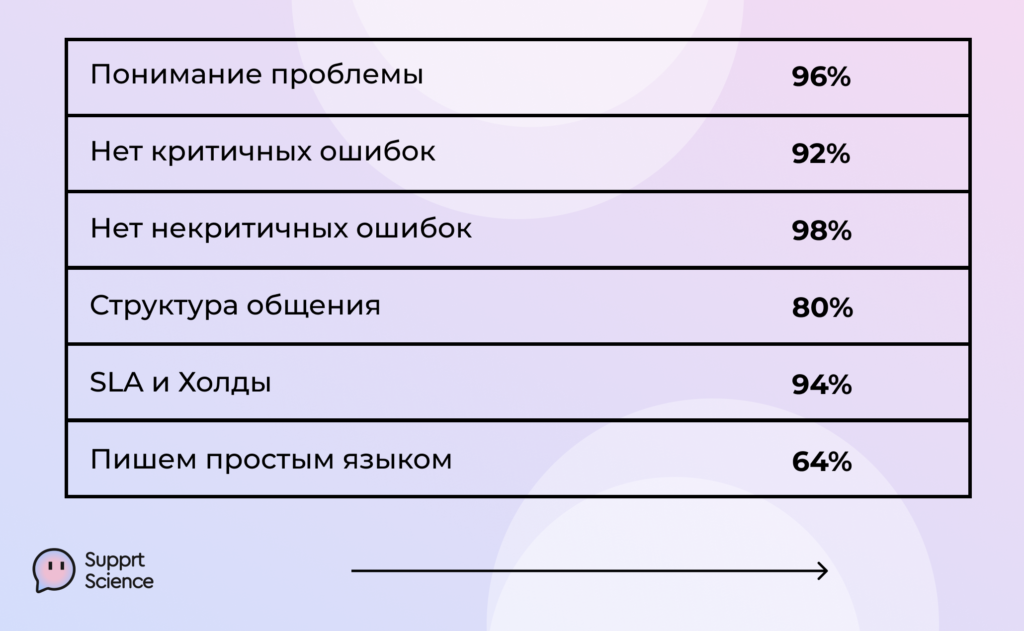
Метрики Успеха — это наши внутренние метрики, по которым мы оцениваем качество коммуникации бота с клиентом. Их шесть:
- Понимание проблемы. Ясна ли боту суть вопроса, насколько хорошо он ориентируется в матчасти.
- Нет критичных ошибок. Бот действует по процедуре верно, отвечает на вопросы корректно.
- Нет некритичных ошибок. К таким ошибкам мы отнесли кейсы, когда бот не проявил проактивности, то есть не сообщил клиенту дополнительные сведения, которые могут быть ему полезны.
- Структура общения. Насколько хорошо и бесшовно бот выстраивает диалог с клиентом, учитывая предыдущие реплики и общий контекст.
- SLA и правила эскалации. Верно ли бот передал задачу человеку, правильно ли сориентировал по срокам, когда нужно будет вернуться к клиенту.
- Простота языка. Бот должен отвечать понятным языком, без канцеляризмов, сложных оборотов и воды.
Метрики рассчитываем в %, где 100% значит, что бот справляется идеально. На данный момент мы видим, что LLM не испытывает трудностей с пониманием клиентского запроса, редко отклоняется от процедуры, оказывает клиентам проактивную поддержку. Это крутой результат. С чем еще предстоит поработать, так это со структурой беседы и умением LLM формулировать ответ лаконично и понятным, простым языком.
А что по результатам?
Нам удалось сократить время обработки одного обращения в 27 раз — с 54 до 2 минут. 54 до 2 минут удалось сократить время обработки обращения Сейчас, спустя полгода после запуска проекта на клиентов, бот уже закрывает 36% обращений, поступающих в чат и на email поддержки. Это достаточно высокий показатель с учетом того, всегда есть часть запросов, с которой гораздо лучше справится человек. Например, когда речь идет о сложных кейсах или эмоциональных клиентах, для работы с которыми нужны опыт и экспертиза.
Что нужно, чтобы сделать из LLM хорошего саппорта?
Если подытожить, то из своего опыта мы выделили четыре основные вещи, которые помогут сделать из GPT отличного помощника как для клиентов, так и для сотрудников поддержки. Это:
- Грамотно настроенный HelpDesk, когда подключены все каналы связи, есть понятные эскалации на вторую и третью линии.
- Актуальные и полные базы данных. Сюда мы относим базы данных о клиентах и Базу Знаний — с подробной информацией о продукте и понятными инструкциями для саппортов.
- Аналитика и статистика по обращениям, чтобы понимать, где есть узкие места, какие пользовательские сценарии нуждаются в проработке, какие правки внести в действующие процедуры.
- Команда, которая будет постоянно повышать качество работы бота. Как минимум проектный менеджер, промт-инженер и разработчик.
Внедряется решение довольно быстро и, по нашим наблюдениям, лучше всего подходит для команд до 100 человек — бот позволяет повысить качество и скорость поддержки, не увеличивая штат. А еще это классное решение для сезонного бизнеса, когда саппорт нужен время от времени, или для компаний с контакт-центром на аутсорсе.
Если вы хотите быть в авангарде технологий и в перспективе снизить косты на поддержку, обращайтесь. Мы не только внедрим LLM-based сервис, но и поделимся экспертизой в промт-инжиниринге.
Illustration by Dani Grapevine from Ouch!


