
 Рассказывает
Рассказывает
Владислав Машталер
Данные и графики изменены в соответствии с требованиями NDA автора
Я — SLA-менеджер в маркетплейсе приложений.
Хочу поделиться опытом, как я совместно со стейкхолдерами сформулировал метрики поддержки, внедрил их во внутренние процессы, и улучшил работу клиентского сервиса.
Сначала про сам SLA-менеджмент. SLA или service-level agreement — соглашение об уровне услуг. Оно определяет уровень обслуживания, который пользователи ожидают от бизнеса, и устанавливает метрики, по которым оценивается уровень оказываемых услуг. Суть SLA-менеджмента — договориться со всеми сторонами, что и как мы хотим мерить, начать измерения и регулярно показывать замеры стейкхолдерам на сервис-ревью, чтобы оценивать результаты работы и планировать мероприятия по улучшению показателей.
Я, как SLA-менеджер, управляю уровнем качества предоставления услуг, в том числе клиентской поддержки, мониторю выполнение SLA, сообщаю о нарушениях и их причинах. Всё это я делаю через метрики.
Что можно определить с помощью метрик поддержки:
- уровень удовлетворенности пользователей;
- время ответа на запросы;
- время решения проблем;
- количество запросов в поддержку;
- другие факторы, которые влияют на работу команды поддержки.
Кому это нужно?
Когда я пришел в команду, функция SLA только формировалась. Отсутствовали чёткие требования, но нужно было понять, где мы сейчас находимся. Мы разработали метрики для поддержки совместно с несколькими заинтересованными сторонами — стейкхолдерами маркетплейса. У каждого были свои задачи.
Подразделение CX (customer experience, клиентский опыт) формулирует метрики, собирает показатели и оценивает уровень и качество клиентского опыта. Их задача — отслеживать процесс взаимодействия пользователя с продуктом во всех точках контакта: мобильное приложение, сайт, поддержка.
C-level маркетплейса работает непосредственно с продуктом. Им метрики нужны для оценки работы поддержки — достаточно ли ресурсов, правильно ли они распределены. C-level наблюдают за динамикой развития уровня лояльности пользователей в точках контакта и анализируют метрики для поиска возможностей улучшить взаимодействие.
Product owners — это люди, непосредственно владеющие частями продукта: мобильное приложение, сайт, админка. Они заинтересованы узнать, как эксплуатируются части продукта, которыми они владеют, каких запросов в поддержку приходит больше всего, и как можно улучшить продукт.
Head of Infra & Support — это руководитель поддержки и инфраструктуры. Он непосредственно отвечает за подразделение поддержки и постоянное повышение качества клиентского сервиса. Для него дашборды по метрикам нужны, чтобы оценивать, что в его подразделении работает хорошо, а что — плохо.
Leads of Support — лиды линий поддержки. Через метрики они отслеживают качество работы консультантов и инженеров поддержки. Могут заметить негативный, просроченный или зависший кейс и разобрать его с командой.
Support consultants and engineers — сотрудники всех линий поддержки, которые еженедельно ознакамливаются с отчетами за прошлую неделю, чтобы оценивать и постоянно поднимать уровень сервиса для клиентов.
Что мы измеряем?
Чтобы понять, насколько эффективно работает поддержка, важно узнать, что происходит с ней в данный момент. Сперва оцениваем volume total и avg ticket time. Первая метрика — общее количество обращений за период: в день, неделю, месяц, квартал, год. А avg ticket time — среднее время цикла жизни всех обращений за выбранный период.
Сравнивая эти две метрики в разные периоды, можно понять, в какие дни или недели поддержка была «на коне», в какие — нет. На коротких отрезках строим графики понедельно, а в квартальных ревью — помесячно.
Вместе с консультантами и инженерами поддержки мы выяснили, почему в разные промежутки времени показания значительно отличаются. Самые серьёзные аномалии связаны с массовыми инцидентами и происходят обычно после крупных релизов. В эти периоды поддержка перегружена, поэтому производительность заметно снижается. Маркетинговые кампании и упоминания в СМИ влияют на производительность аналогичным образом.
В обычные дни скорость обработки обычно снижена в утренние часы — в это время сотрудники разбирают не только новые обращения, но и те, которые скопились за ночь. При любом скоплении обращений неизбежно растёт показатель avg ticket time.
Вот как мы считаем avg ticket time.
Высчитываем разницу дат закрытия к открытию обращения из системы и получаем среднее по тикету. Хорошо это или плохо? Стоит выяснить: берем количество людей, обращений, среднее время закрытия тикета, здравый смысл и думаем, удовлетворяет нас такое время или нет.
Если, допустим, вам приходит 1000 обращений в день, среднее время обработки — 12 минут, и стейкхолдеров оно устраивает, то всё хорошо. Если же посыпались 4000 обращений, и среднее время работы над каждым стало 46 минут, значит, есть проблемы, например, не хватает ресурсов.
Службам клиентского сервиса не всегда понятно, как оценивать среднее время работы с обращением, поэтому мы советовались непосредственно с бизнесом, как с основным заказчиком. Пришли к тому, что за 12 часов должно обрабатываться 80% обращений, за 24 часа — 90%, за 72 часа — 100% обращений.
У нас есть три показателя, заказчиком которых является CX.
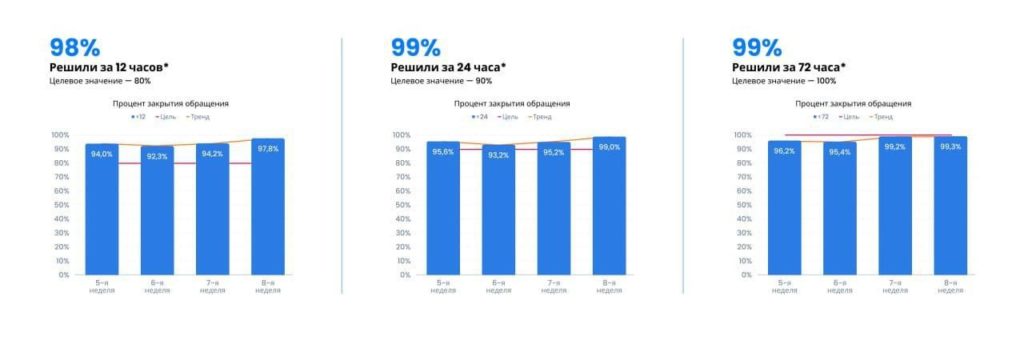
На графиках слева направо показано понедельное выполнение показателей по доле обращений, выполненных за 12, 24 и 72 часа. В отчет попадают только созданные и уже закрытые обращения. Мы договорились не включать и не считать затянувшиеся обращения, но на месячных и квартальных ревью смотреть все.
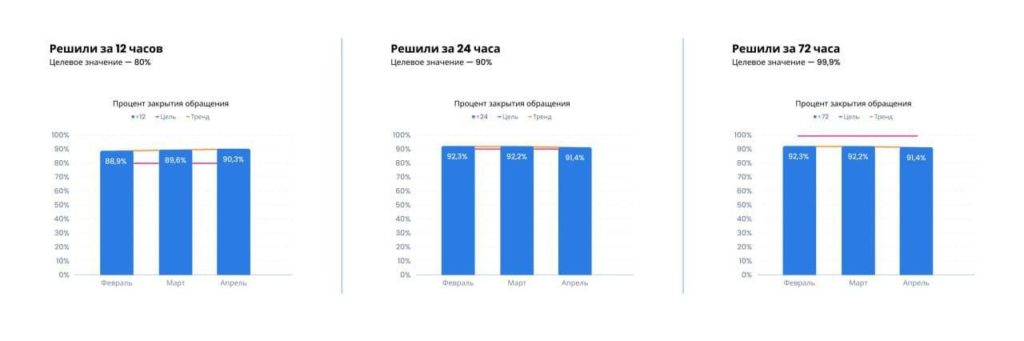
После того, как начали мерить volume total и avg ticket time, мы поняли, что у нас болит:
- нам критически не хватало понятного процесса инцидент-менеджмента и человека на роль инцидент-менеджера;
- очень нужны были инструменты для решения запросов на изменение, потому что поддержке запрещено давать доступ кому-либо в базу данных продакшн-окружения;
- не было необходимых инструментов в админке для решения запросов на изменения, а их разработка не была в приоритете.
Исходя из этих вводных, мы разработали активности и мероприятия, которые должны были повлиять на уровень показателей:
- подняли приоритет для задач по разработке инструментария,
- взяли в команду поддержки инцидент-менеджера;
- разработали процесс, при котором 24/7 есть дежурные разработчики для хотфиксов.
Главное, что мы сделали для консультантов и инженеров, — разместили счетчики времени обработки тикета прямо в теле обращения, чтобы каждый сотрудник мог понимать, сколько времени на обработку запроса у него осталось. Для этого выставили целевое время.
Вычисляем целевое время
Есть два пути формулирования целевых сроков жизненного цикла обращения:
- Теоретический путь, или «от клиента». Это ситуация, когда мы смотрим на время обращения со стороны клиента и выдвигаем гипотезу за него: решаем, за сколько комфортно для клиента решение обращения. Минус этого варианта в том, что могут потребоваться дополнительные ресурсы, например, больше сотрудников для ускорения обработки потока входящих обращений. У клиента всегда очень завышенные цели: ему нужно максимально быстро решить вопрос.
- Путь, исходящий из текущего положения дел. В этом варианте мы смотрим на количество обращений и среднее время жизненного цикла обращения. Делим обращения на типы и категории, оцениваем текущее среднее время по каждой из категорий: консультации — быстрее, запросы на изменение — дольше, инциденты — чаще всего, еще дольше.
Мы пошли с двух сторон: настроили счетчики в системе регистрации обращений и начали смотреть, за сколько решаем каждый вопрос сейчас, а параллельно сформулировали желательное время закрытия проблемы, которое бы удовлетворило пользователей.
По факту, мы поставили две цели: в ближайшем будущем решать 80% обращений за 12 часов, а на перспективу — сократить время до 60 минут. Это позволило понять, что мы можем сделать текущими ресурсами, а какие мероприятия нужны для достижения амбициозных целей: нарастить кадровый потенциал и доработать системы администрирования.
Разделяем обращения
Следующим этапом мы взялись за категоризацию обращений. Разработали критерии для категорий, актуализировали, согласовали и настроили по системе счетчики.
Обращения мы поделили на следующие типы:
- консультации;
- запросы на обслуживание;
- запросы на изменение;
- инциденты.
И внедрили приоритеты:
- блокирующий;
- критический;
- стандартный;
- минорный.
Для каждой пары «тип + приоритет» назначили целевое время решения обращения: от 4 до 72 часов в рабочем графике поддержки. Также договорились, что время первой реакции для каждой линии составит 30 минут.
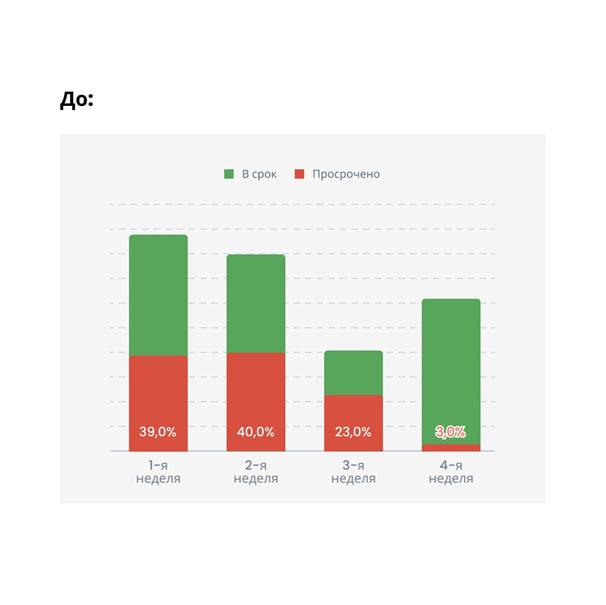
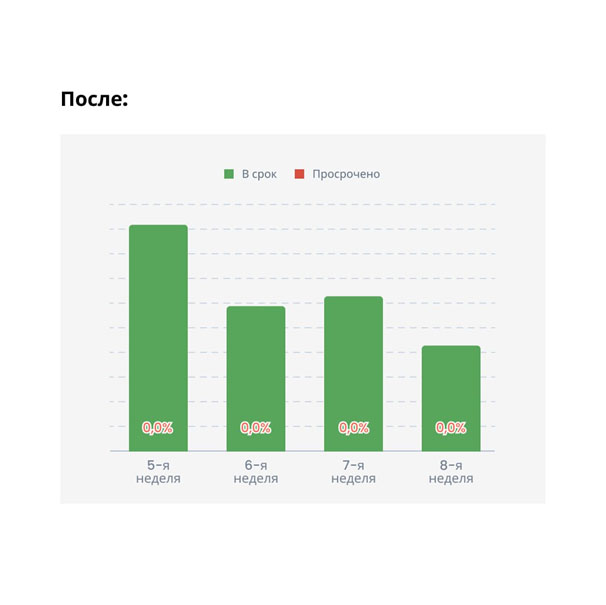
Через неделю мы смогли считать выполненные в срок обращения и просроченные. И вновь первое, что нам помогло для повышения показателей, — размещение счетчиков в теле обращения. Сотрудник поддержки видит таймер, понимает, сколько у него времени, и решает обращение вовремя.
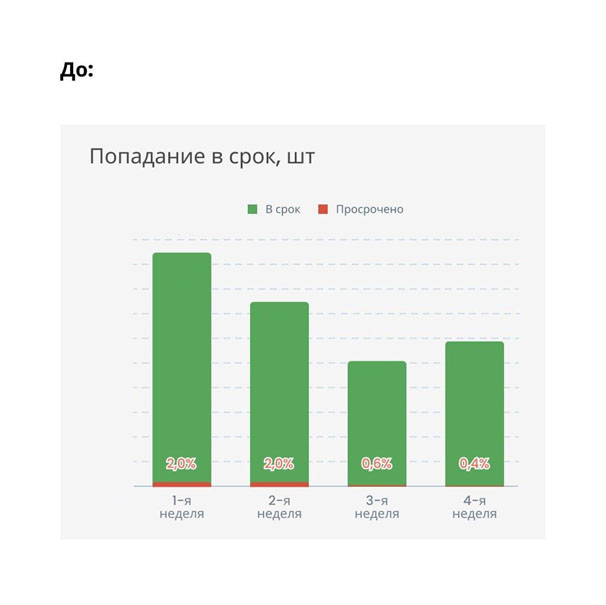
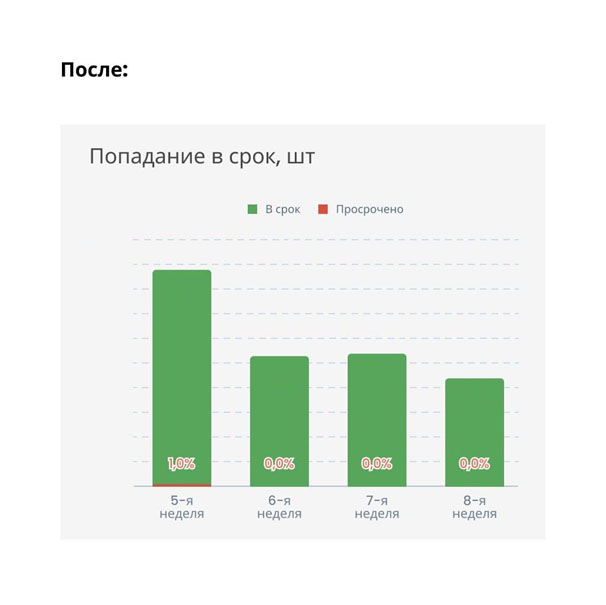
А вот графики по реакции третьей линии:
Чиним каталог тематик
Следующим мероприятием была переработка существующего и нефункционального каталога тематик обращений в поддержку. Поле «Тематика» есть для каждого обращения и обязательно для заполнения при назначении исполнителя. Каталог тематик был максимально детализирован, потому что тематики формулировались еще до старта работы поддержки, из-за этого документ был перегружен.
При сортировке обращений первая линия не находила релевантной тематики, поэтому большинство тикетов складывалось в «Прочее». Выяснилось, что корректное заполнение поля «Тематика» требовало времени и не имело никакой практической пользы: после закрытия обращения никто не анализировал статистику по тематикам.
Мы разделили каталог на уровни. Первый уровень тематик мы сформулировали из частей продукта: «Мобильное приложение», «Админская панель», «Интеграции» и так далее. Во второй уровень включили самые распространенные тематики по частям продукта, например, «Мобильное приложение» → «Проблемы c UI».
После переработки каталога мы смогли выявлять самые уязвимые места продукта и передавать Product owners информацию для постоянного улучшения.
Топ тематик входит в еженедельные сервис-ревью. Раз в 1–2 месяца мы проводим аналитику по обращениям и добавляем, меняем или удаляем неактуальные тематики. После введения работающего каталога стало максимально удобно считать статистику по обращениям в любом разрезе по первому требованию бизнеса.
Считаем долю обращений
Одна из очень важных метрик любого многоуровневого клиентского сервиса, которая показывает и подготовку первой линии, и инструментарий второй линии, и качество передачи знаний от третьей линии к первым двум, — это доля переданных обращений с первой на вторую и со второй на третью линии.
Тут всё просто: доля переданных обращений с первой на вторую линию не должна превышать 20%, со второй на третью линию — тоже не более 20%. Это отраслевой стандарт.
В статистике считаются все обращения за исключением массовых инцидентов, их мы обозначаем метками в случае возникновения и исключаем из общей статистики.
В сухом остатке, чтобы начать мерить поддержку, достаточно посчитать объем потока обращений, количество сотрудников и среднее время решения обращения. Для детализации необходимо разделить обращения на типы и приоритеты, а потом расставить время выполнения для каждой пары. Для контроля обращений по частям продукта или по сервисам — ввести рабочий каталог тематик. И для того, чтобы иметь возможность отслеживать качество работы каждой линии, нужно определить долю обращений, переданных на следующую линию. Таков путь.
Illustration by Oleg Shcherba from Ouch!


